
وبکلاسترها، که به نامهای دیگری همچون خزندههای وب یا رباتهای جستجو نیز شناخته میشوند، برنامههایی هستند که به طور خودکار از طریق اینترنت محتوا را کاوش کرده و اطلاعات را جمعآوری میکنند. این ابزارها به عنوان سنگ بنای موتورهای جستجو عمل میکنند و برای نمایهسازی محتوای وب و ارائه نتایج دقیق به کاربران طراحی شدهاند. در این مقاله به بررسی انواع خزندهها و نحوه کار آنها خواهیم پرداخت.
فهرست مطالب
Web Crawler چیست؟
Web Crawler یا خزنده وب، یک برنامه یا روبات خودکار است که به منظور جمعآوری اطلاعات از وبسایتها و صفحات مختلف اینترنت، طراحی شده است. این ابزار بهطور معمول بهعنوان جزء اصلی موتورهای جستجو عمل میکند و نقش کلیدی در فهرستبندی محتوای موجود در وب ایفا میکند. در ادامه به بررسی جزئیات و عملکرد خزندههای وب خواهیم پرداخت.
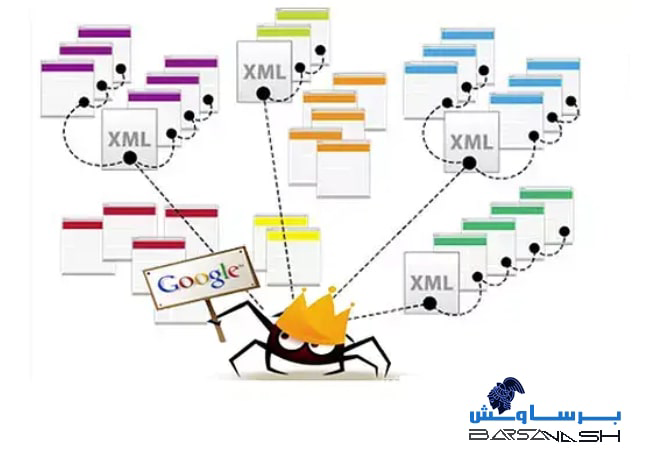
عملکرد Web Crawler
خزندههای وب معمولا با شروع از یک یا چند صفحه وب مشخص، فرآیند جستجو را آغاز میکنند. این خزندهها به طور خودکار به لینکهای موجود در صفحات مراجعه کرده و به جمعآوری دادهها ادامه میدهند. فرآیند کار خزندههای وب به مراحل زیر تقسیم میشود:
- جمعآوری URLها: خزندهها با بررسی محتوای صفحه، URLهای موجود را شناسایی و به یک فهرست اضافه میکنند.
- دنبال کردن لینکها: خزنده پس از جمعآوری URLها، به سراغ لینکها میرود و محتوای صفحات جدید را بازدید میکند.
- تحلیل و استخراج داده: هنگامی که خزنده به یک صفحه جدید میرسد، محتوای آن را تحلیل کرده و اطلاعات مفید را استخراج میکند. این اطلاعات ممکن است شامل متن، تصاویر، ویدئوها و متا دیتاها باشد.
- فهرستبندی اطلاعات: پس از جمعآوری و تحلیل دادهها، خزندهها این اطلاعات را در پایگاههای داده خود ذخیره میکنند تا در زمان جستجوی کاربران، به سرعت به آنها دسترسی پیدا کنند.
اهمیت Web Crawler
خزندههای وب برای موتورهای جستجو اهمیت بالایی دارند و به آنها کمک میکنند تا محتوای وب را بهروزرسانی و فهرستبندی کنند. این ابزارها امکان جستجوی سریع و کارآمد اطلاعات را برای کاربران فراهم میکنند و باعث میشوند که محتوای جدید به سرعت در دسترس قرار گیرد.
چالشها و محدودیتها
با وجود اهمیت بسیار خزندههای وب، آنها با چالشها و محدودیتهایی نیز مواجه هستند. به عنوان مثال:
- محتوای دینامیک: صفحات وب که به صورت دینامیک بارگذاری میشوند ممکن است توسط خزندهها بهدرستی شناسایی نشوند.
- نظم و ساختار وب: ساختار پیچیده وبسایتها و تعداد بالای لینکها میتواند باعث شود که خزندهها بهراحتی نتوانند به تمام صفحات دسترسی پیدا کنند.
- سیاستهای دسترسی: برخی وبسایتها با استفاده از فایلهای
robots.txtو سایر متدها دسترسی خزندهها به محتوای خود را محدود میکنند.
بهطور کلی، Web Crawlerها ابزاری حیاتی در دنیای دیجیتال هستند که به موتورهای جستجو کمک میکنند تا به طور کارآمد اطلاعات را جمعآوری و فهرستبندی کنند و تجربهای بهتر برای کاربران به ارمغان بیاورند.
وظایف رباتهای خزنده
رباتهای خزنده، که به عنوان “خزندهها” یا “اسکراپرها” نیز شناخته میشوند، از جمله ابزارهای حیاتی در دنیای دیجیتال به شمار میروند. این برنامههای خودکار به وب سایتها سر میزنند و اطلاعات مختلفی را جمعآوری و تجزیه و تحلیل میکنند. در ادامه به بررسی وظایف اصلی این رباتها میپردازیم:
۱. جمعآوری اطلاعات
رباتهای خزنده به منظور جمعآوری اطلاعات از وبسایتها برنامهریزی شدهاند. این اطلاعات میتواند شامل متن، تصاویر، لینکها و سایر دادههای موجود در صفحات وب باشد. این فرآیند به موتورهای جستجو کمک میکند تا بتوانند محتوای وبسایتها را به راحتی شناسایی و طبقهبندی کنند.
۲. ایندکسگذاری
پس از جمعآوری اطلاعات، رباتهای خزنده وظیفه ایندکسگذاری صفحات مختلف وبسایتها را بر عهده دارند. ایندکسگذاری به معنای سازماندهی و ذخیرهسازی اطلاعات در پایگاههای داده موتورهای جستجوست. این مرحله Critically برای نمایش نتایج جستجو به کاربران ضروری است.
۳. بهروزرسانی اطلاعات
وبسایتها به طور مداوم در حال تغییر و بهروزرسانی محتوا هستند. رباتهای خزنده به روزرسانی اطلاعات را پیگیری کرده و هر بار که تغییراتی در صفحات رخ میدهد، آن را ثبت و در پایگاههای دادهی مربوطه بهروزرسانی میکنند. این عمل به موتورهای جستجو کمک میکند تا محتوای جدید را در نتایج جستجو به کاربران نمایش دهند.
۴. بررسی کیفیت و ساختار وبسایت
رباتهای خزنده توانایی تجزیه و تحلیل کیفیت و ساختار وبسایتها را دارند. آنها میتوانند مشکلاتی چون لینکهای خراب، بارگذاری کند صفحات یا کیفیت پایین محتوا را شناسایی کنند. این اطلاعات به وبمستران کمک میکند تا نقاط ضعف وبسایت خود را اصلاح کنند و تجربه کاربری بهتری ارائه دهند.
۵. تحلیل دادهها
در نهایت، رباتهای خزنده وظیفه تحلیل دادهها را نیز بر عهده دارند. آنها میتوانند روندهای خاصی را شناسایی کنند و به شرکتها و سازمانها در تصمیمگیریهای استراتژیک کمک کنند. این تحلیلها میتواند شامل تجزیه و تحلیل ترافیک وب، رفتار کاربر و عملکرد محتوا باشد.
در نهایت، رباتهای خزنده به عنوان ابزارهای کلیدی در دنیای وب عمل میکنند و نقش مهمی در بهبود کیفیت دادهها، ایندکسگذاری مؤثر و ارائه نتایج جستجو دارند. آگاهی از وظایف این رباتها میتواند به وبمستران و صاحبان کسبوکار کمک کند تا راهکارهای بهتری برای بهینهسازی وبسایتهای خود ارائه دهند.
تفاوت کراولینگ و ایندکسینگ
در دنیای وب و سئو، دو واژه مهم وجود دارد که در فرآیند نمایش صفحات وب در نتایج جستجو نقش اساسی دارند: کراولینگ (Crawling) و ایندکسینگ (Indexing). در این بخش به بررسی تفاوتهای این دو مفهوم پرداخته و اهمیت هر یک در بهینهسازی موتورهای جستجو را مورد بحث قرار میدهیم.
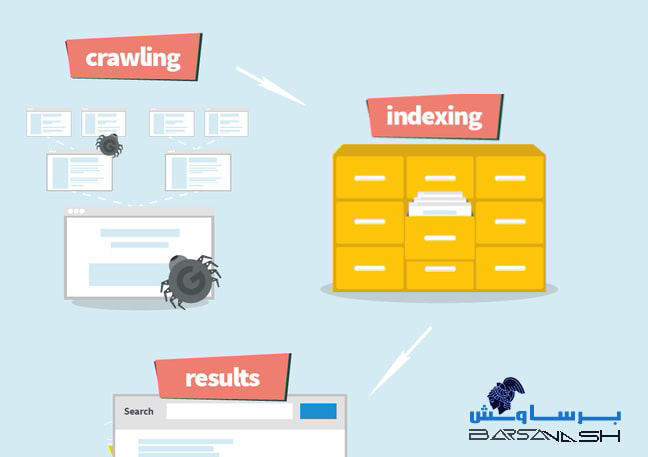
کراولینگ چیست؟
کراولینگ به فرآیند جستجو و بررسی صفحات وب توسط رباتهای موتور جستجو گفته میشود. این رباتها که به آنها “کراولر” یا “اسپایدر” نیز گفته میشود، به طور مداوم به وبسایتها سر میزنند و لینکها را دنبال میکنند. هدف اصلی کراولینگ جمعآوری اطلاعات در مورد محتوا و ساختار صفحات وب است، تا موتورهای جستجو بتوانند بفهمند یک صفحه چه موضوعی را پوشش میدهد.
ایندکسینگ چیست؟
پس از اینکه رباتهای موتور جستجو یک صفحه وب را کراول کردند، اطلاعات جمعآوری شده به مرحلهای به نام ایندکسینگ منتقل میشود. ایندکسینگ به فرآیند ذخیرهسازی و سازماندهی اطلاعات صفحات وب در پایگاه داده موتور جستجو اشاره دارد. موتورهای جستجو تمام اطلاعات مربوط به صفحات وب را دستهبندی کرده و آنها را به گونهای سازماندهی میکنند که در صورت جستجو توسط کاربران، به راحتی قابل دسترسی باشند.
تفاوتهای کلیدی بین کراولینگ و ایندکسینگ
- هدف:
- کراولینگ به جمعآوری اطلاعات مربوط به صفحات وب میپردازد.
- ایندکسینگ به ذخیره و سازماندهی این اطلاعات در پایگاه داده موتور جستجو مرتبط است.
- زمانبندی:
- کراولرها به طور همیشگی و در زمانهای مرتب صفحات را بررسی میکنند.
- ایندکسینگ پس از کراولینگ و به صورت دورهای انجام میشود.
- نقش در سئو:
- کراولینگ اولین قدم در فرایند سئو است؛ بدون آن، هیچ صفحهای دیده نخواهد شد.
- ایندکسینگ تضمینکننده این است که صفحات کراول شده در نتایج جستجو نمایش داده شوند.
در نهایت، درک تفاوتهای میان کراولینگ و ایندکسینگ میتواند به صاحبان وبسایتها کمک کند تا استراتژیهای سئوی موثری را پیادهسازی کنند. با بهینهسازی محتوای خود و استفاده از بهترین روشها، امکان بهبود شانس کراول و ایندکس صفحات وب افزایش مییابد، که در نهایت به افزایش ترافیک و رونق کسبوکار منجر میشود.
انواع کراولرهای وب
کراولرها، نرمافزارهای خودکار هستند که وظیفه پیمایش و جمعآوری اطلاعات از صفحات وب را بر عهده دارند. این ابزارها، نقش اساسی در عملکرد موتورهای جستجو، وبسایتهای مانیتورینگ و بسیاری از اپلیکیشنهای دیگر ایفا میکنند. با توجه به هدف و وظیفه، انواع مختلفی از کراولرها وجود دارد که هر کدام برای جمعآوری نوع خاصی از دادهها طراحی شدهاند.

کراولرهای عمومی (General-Purpose Crawler)
این دسته از کراولرها، برای پیمایش و جمعآوری اطلاعات کلی صفحات وب طراحی شدهاند. هدف اصلی آنها، کشف و فهرستبندی صفحات جدید و بروزرسانی شده در وب است. موتورهای جستجو، مانند گوگل، از این نوع کراولرها برای ایجاد و بهروزرسانی پایگاه داده عظیم خود از اطلاعات وب استفاده میکنند. این کراولرها به طور معمول الگوریتمهای پیچیدهای برای پیمایش هوشمندانه و بهینه صفحات وب دارند تا از اتلاف منابع جلوگیری کنند. آنها بر اساس قوانین وب، مانند رباتهای مخفی (robots.txt) و سرعت پاسخ وبسایتها کار میکنند تا از بار اضافی بر سرورها جلوگیری شود.
کراولر بک لینک (Backlink Crawler)
این نوع کراولرها به طور اختصاصی برای جمعآوری اطلاعات بک لینکها طراحی شدهاند. آنها صفحات وب را بررسی میکنند تا لینکهای ورودی به آن صفحه را بیابند و اطلاعات مربوط به منبع، متن و سایر ویژگیهای لینک را ثبت کنند. این اطلاعات برای تجزیه و تحلیل رتبهبندی وبسایتها، شناسایی رقیبان و درک ساختار لینکدهی در اینترنت به کار میرود. این اطلاعات برای بهینهسازی سئو (SEO) و بهبود رتبهبندی وبسایتها حیاتی است.
کراولر مدیا (Media Crawler)
این نوع کراولرها بر روی جمعآوری و استخراج اطلاعات مربوط به محتوای رسانهای در وب متمرکز هستند. آنها میتوانند فایلهای تصویری، ویدئویی، صوتی و سایر فرمتهای رسانهای را شناسایی، جمعآوری و ذخیره کنند. کاربردهای این نوع کراولرها در وبسایتهای اشتراکگذاری محتوا، موتورهای جستجوی رسانهای، و خدمات تحلیل دادههای رسانهای متنوع است. مثلاً در تحلیل ریتم تولید محتوا و نوع محتواهای پرطرفدار استفاده می شوند.
کراولر محتوا (Content Crawler)
این کراولرها به طور خاص برای جمعآوری و استخراج متن و دادههای ساختاری صفحات وب طراحی شدهاند. هدف آنها، استخراج محتوا، شناسایی کلیدواژهها، تجزیه و تحلیل سبک نگارش، و استخراج اطلاعات مربوط به ساختار محتوایی صفحات است. این نوع کراولرها میتوانند برای اهداف مختلفی مانند تولید محتوای جدید، تحلیل رقابت، و بهبود سئو وبسایتها به کار روند. همچنین میتوانند دادههای وبسایتها را برای مقایسه با استانداردهای موجود یا کشف الگوهای تکراری مورد بررسی قرار دهند.
نحوه کار Crawler
Crawler یا رباتهای جستجو، نرمافزارهایی هستند که به طور مداوم وبسایتها را کاوش کرده و اطلاعات آنها را جمعآوری میکنند. این ابزارها به موتورهای جستجو کمک میکنند تا محتوای آنلاین را ایندکس کنند و به کاربران نتایج مرتبط ارائه دهند. در ادامه به بررسی اهمیت صفحههای وب، بازدید مجدد از آنها و همچنین استراتژی فایل robots.txt خواهیم پرداخت.
اهمیت نسبی صفحهی وب
اینکه یک صفحه وب در مقایسه با دیگر صفحات وب چقدر مهم است، تحت تأثیر عوامل مختلفی قرار دارد. برخی از این عوامل شامل کیفیت محتوا، تعداد و کیفیت لینکهای ورودی به صفحه، و میزان تعامل کاربران با آن محتوا میباشد. موتورهای جستجو برای ارزیابی اهمیت نسبی صفحات از الگوریتمهای پیچیدهای استفاده میکنند. این اهمیت به طور مستقیم بر رتبهبندی صفحه در نتایج جستجو تأثیر میگذارد و در نتیجه بر ترافیک وبسایت نیز اثر گذار است.
بازدید مجدد از همان صفحه
Crawlerها به طور دورهای از صفحات وب بازدید میکنند تا هر گونه تغییر در محتوا، لینکها یا ساختار صفحه را شناسایی کنند. این بازدید مجدد اجازه میدهد تا موتور جستجو اطلاعات جدید را ایندکس کرده و کاربران را با نتایج بروزرسانی شده ارائه دهد. همچنین، تعداد دفعات بازدید Crawler از یک صفحه میتواند نشانهای از اهمیت آن صفحه باشد. صفحاتی که به طور مکرر بهروزرسانی میشوند، معمولاً مورد توجه بیشتری قرار میگیرند.
استراتژی فایل Robots.txt
فایل robots.txt ابزاری است که به مدیران وبسایتها این امکان را میدهد که تعیین کنند کدام بخشها از سایت باید توسط Crawlerها ایندکس شوند و کدام بخشها باید از این پروسه مستثنی گردند. با استفاده از این فایل، میتوان از ایندکس شدن محتواهای حساس یا غیرضروری جلوگیری کرد. بهعلاوه، استفاده مؤثر از فایل robots.txt میتواند به بهینهسازی Crawl Budget کمک کند، که به مقدار زمان و منابعی که Crawlerها برای کاوش یک وبسایت صرف میکنند، اشاره دارد.
در نهایت، تمام این عوامل به بهبود راندمان و کارایی Crawlerها کمک میکند و موجب میشود که موتورهای جستجو بتوانند به بهترین نحو ممکن اطلاعات مربوط به صفحات وب را در اختیار کاربران قرار دهند.
تفاوت وب کراولینگ و وب اسکریپتینگ
وب کراولینگ و وب اسکریپتینگ هر دو تکنیکهایی هستند که به دسترسی و استخراج داده از وب کمک میکنند، اما با اهداف و روشهای متفاوتی عمل میکنند. درک تفاوت این دو تکنیک برای تصمیمگیری صحیح در مورد ابزارها و استراتژیهای دادهکاوی ضروری است.
وب کراولینگ (Crawling)
وب کراولینگ به معنای پیمایش سیستماتیک صفحات وب است. یک وب کراولر (یا خزنده وب) بهصورت رباتیک، صفحات وب را کشف، پیمایش و اطلاعات آنها را ثبت میکند. هدف اصلی وب کراولینگ، ساخت یک فهرست از صفحات وب و اطلاعات مرتبط با آنها برای موتورهای جستجو مانند گوگل است. این فهرست به موتورهای جستجو کمک میکند تا صفحات مرتبط با جستجوهای کاربران را سریعتر و مؤثرتر پیدا کنند. این فرایند شامل بررسی پیوندهای موجود در صفحات وب و دنبال کردن آنها برای کشف صفحات جدید است. مهمترین خروجی وب کراولینگ، ساخت نقشه (Map) از ساختار وب است، نه استخراج دادههای خاص.
ویژگیهای کلیدی وب کراولینگ:
- هدف کلی: فهرستبندی و سازماندهی صفحات وب برای موتورهای جستجو
- عملیات: پیمایش لینکها و کشف صفحات جدید
- نوع داده: دادههای ساختاری وب (مانند ساختار، لینکها، عناوین، متا تگها)
- خروجی: نقشه و فهرست صفحات وب
وب اسکریپتینگ (Scripting)
وب اسکریپتینگ فرایندی است برای استخراج دادههای خاص از صفحات وب. در این روش، کد اسکریپت (معمولاً با زبانهای برنامهنویسی مانند Python، JavaScript) نوشته میشود که به مرورگر وب اجازه میدهد تا با صفحات وب تعامل کند و اطلاعات خاصی را از آنها استخراج کند. هدف اصلی وب اسکریپتینگ، استخراج دادههای خاص و قابلکاربرد برای تحلیل و یا کاربرد در برنامههای دیگر است.
ویژگیهای کلیدی وب اسکریپتینگ:
- هدف خاص: استخراج دادههای دقیق و مرتبط از صفحات وب
- عملیات: تعامل با صفحات وب و استخراج دادههای هدفمند
- نوع داده: هر نوع دادهای که در صفحه وب یافت میشود (متن، تصاویر، ویدئوها، دادههای جدول و …)
- خروجی: دادههای استخراجشده در قالبهای مختلف (مانند فایلهای CSV، دادههای پایگاه داده، یا دادههای موجود در یک برنامه دیگر).
اهمیت وب کراولرها روی سئو سایت
وب کراولرها، بخش اساسی و گاهی نادیده گرفته شده از زیرساخت سئو هستند. درک چگونگی کارکرد آنها و تأثیرشان بر رتبهبندی سایت در موتورهای جستجو، برای هر متخصص سئو حیاتی است. در این بخش به بررسی اهمیت وب کراولرها در بهینه سازی موتور جستجو (SEO) میپردازد.
تاثیر مستقیم بر سئو
عملکرد وب کراولرها به طور مستقیم بر سئو سایت تأثیر میگذارد:
- کشف محتوا: وب کراولرها محتوای جدید و بهروزرسانی شده را کشف میکنند. اگر محتوای سایت به درستی توسط کراولرها قابل دسترس نباشد، موتور جستجو نمیتواند آن را در فهرست خود قرار دهد. این موضوع به ویژه برای سایتهایی که محتواهای زیادی تولید و آپدیت میکنند، اهمیت بسیاری دارد.
- شناسایی لینکها: کراولرها با دنبال کردن لینکها، ارتباط بین صفحات مختلف یک وبسایت و همچنین بین وبسایتها را شناسایی میکنند. این ارتباطات، نقشه کلی ساختار سایت را برای موتور جستجو ترسیم میکنند و در درک موضوعات و ارتباط آنها مؤثرند.
- ارزیابی کیفیت ساختار وبسایت: کراولرها به بررسی ساختار سایت از نظر سرعت بارگذاری صفحات، استفاده از تکنولوژیهای مدرن و دیگر عوامل فنی مرتبط با تجربه کاربری میپردازند. وبسایتهای با ساختار ضعیف یا صفحات پر از خطا، برای کراولرها مشکل ایجاد میکنند و این مساله میتواند در رتبهبندی سایت تأثیرگذار باشد.
- تشخیص و رفع خطاهای فنی: کراولرها خطاهای فنی مانند لینکهای شکسته، صفحات با خطاهای HTTP، مشکلات در فایلهای Robots.txt و دیگر اختلالات را شناسایی میکنند و گزارش میدهند. این اطلاعات میتواند در بهبود سئو و افزایش کارایی سایت مورد استفاده قرار گیرد.
- بهبود سئو داخلی و خارجی: با شناسایی ساختار، محتوای داخلی و خارجی سایت، کراولرها به موتور جستجو کمک میکنند تا صفحات مهم را در نتایج جستجو قرار دهد.
اهمیت بهینه سازی برای وب کراولرها
بهینهسازی وبسایت برای وب کراولرها، به معنی افزایش کارایی و سهولت دسترسی کراولرها به محتوا و ساختار سایت است. این بهینه سازی شامل موارد زیر است:
- بهینهسازی سرعت بارگذاری صفحات: صفحات سریعتر، تجربه کاربری بهتری را ارائه میدهند و برای کراولرها نیز راحتتر قابل دسترس هستند.
- بهینهسازی فایل Robots.txt: با مشخص کردن صفحات و بخشهای غیرضروری برای کراولرها، میتوان منابع و زمان کراولرها را بهینه کرد.
- بهینهسازی ساختار URL: URLهای واضح و مختصر، به کراولرها کمک میکنند تا موضوع صفحه را به راحتی درک کنند.
- استفاده از تگهای مناسب: استفاده درست از تگهای HTML، مانند تگهای عنوان، متا توضیحات و تگهای Alt، به موتور جستجو کمک میکنند تا محتوای صفحه را بهتر درک کنند.
- ساختار نقشه سایت (Sitemap): نقشه سایت به کراولرها نشان میدهد که چه بخشهایی از سایت برای آنها قابل دسترس هستند.
در نتیجه، درک و بهینهسازی برای وب کراولرها، عنصری حیاتی در استراتژی سئو موفق است. با افزایش کارایی وب کراولرها، رتبهبندی سایت در نتایج جستجو بهبود مییابد و در نهایت، بازدید و فروش به طور قابل ملاحظهای افزایش پیدا میکند.
سؤالات متداول
WebCrawler چیست و چه میکند؟
Web Crawler به طور خودکار صفحات وب را میگردد و اطلاعات موجود در آنها را جمعآوری میکند. این اطلاعات شامل متن، تصاویر، ویدئوها، و سایر محتواها میشود. هدف اصلی آن، ایجاد یک فهرست جامع از صفحات وب است که موتورهای جستجو میتوانند از آن برای پاسخگویی به جستجوی کاربران استفاده کنند.
چگونه یک Web Crawler کار میکند؟
یک Web Crawler از یک مجموعه از الگوریتمها و قواعد برای پیمایش وب استفاده میکند. این الگوریتمها به آن اجازه میدهند تا صفحات جدید را کشف و پیوندهای موجود در آن صفحات را دنبال کنند. همچنین، قواعدی وجود دارد که Crawler را از خزش بیرویه و آسیب به سرورها باز میدارد.
تفاوت بین Web Crawler و Spider چیست؟
هر دو اصطلاح به یک مفهوم اشاره دارند. اصطلاح Web Crawler عموما در زمینههای فنی تر و تخصصی تر استفاده میشود، در حالی که Spider برای بیان عمومی تر و قابل فهمتر این مفهوم به کار میرود.
مهمترین فاکتورهای موثر بر عملکرد یک Web Crawler چیست؟
عوامل مهم عبارتند از: * سرعت و کارایی: Crawler باید بتواند صفحات را به طور کارآمد و با سرعت بالا پردازش کند. * استراتژی پیمایش: الگوریتم پیمایش باید به گونهای طراحی شود که به طور موثر صفحات جدید را کشف و محتواهای مرتبط را جمعآوری کند. * محافظت از منابع: Crawler باید از بارگذاری بیش از حد سرورهای وب جلوگیری کند و به سیاستهای وبسایتها احترام بگذارد. * پشتیبانی از انواع دادهها: باید قادر به پردازش انواع مختلف داده، از جمله متن، تصویر و ویدئو باشد.
چگونه میتوان از یک Web Crawler برای استخراج داده استفاده کرد؟
یک Web Crawler را میتوان برای استخراج دادههای خاص از وبسایتها، مانند اطلاعات قیمت، نظرات مشتریان یا دیگر اطلاعات ساختاری، مورد استفاده قرار داد. این دادهها سپس برای اهداف مختلفی، از جمله تحلیل بازار، تصمیمگیری و غیره استفاده میشوند.
چه محدودیتهایی برای Web Crawler وجود دارد؟
- محدودیتهای ربات: وبسایتها میتوانند از روباتهای اجتنابکننده برای محدود کردن خزش استفاده کنند.
- محدودیتهای فنی: Web Crawler ممکن است نتواند به برخی صفحات خاص دسترسی پیدا کند.
- سرعت محدود: پیمایش کامل وب یک فرآیند زمانبر و پیچیده است.
- تغییرات وبسایتها: محتوا و ساختار صفحات وب دائما تغییر میکند که میتواند روی کارایی Crawler اثر بگذارد.
کاربردهای Web Crawler چیست؟
کاربردهای این ابزار بسیار گسترده است و شامل: * موتورهای جستجو: فهرستبندی صفحات وب برای جستجوی کاربر * استخراج اطلاعات: جمعآوری دادههای خاص از وبسایتها * پایش قیمتها: نظارت بر تغییرات قیمت در وب * شناسایی الگوها: شناسایی الگوهای در دادههای وب * تولید محتوای خودکار: ایجاد محتوای جدید بر اساس دادههای استخراجشده.
آیا Web Crawler میتواند به وبسایتها آسیب برساند؟
استفاده نادرست و بیرویه از Web Crawler میتواند به سرورهای وبسایت آسیب برساند. رعایت محدودیتهای ربات و سیاستهای وبسایت ضروری است.
